Summary
The development of Large Language Models (LLMs) has opened many new doors for processing data and automating tedious tasks based on natural language. One common mistake people make is overestimating the capabilities of LLMs. LLMs are extremely powerful, but we have to be careful not to just throw any problem at the model and expect it to magically give the best solution. This is especially important when using LLMs at scale and in systems where mistakes are less and less acceptable.
LLMs are naturally non-deterministic, meaning their outputs may change whenever given the same input. In practice, this leads to some responses being much better than others, just by how the model processed the query. When we apply an LLM in a system, we expect it to consistently provide accurate, relevant information and perform tasks properly. This is when the non-determinism of the model may become an issue. How can we guarantee the LLM will behave how we want it to every time?
Another issue we can run into with LLMs is that they are limited to the information on which they were trained. When LLaMA was asked what the weather is currently like in Lexington, KY, it reported this:
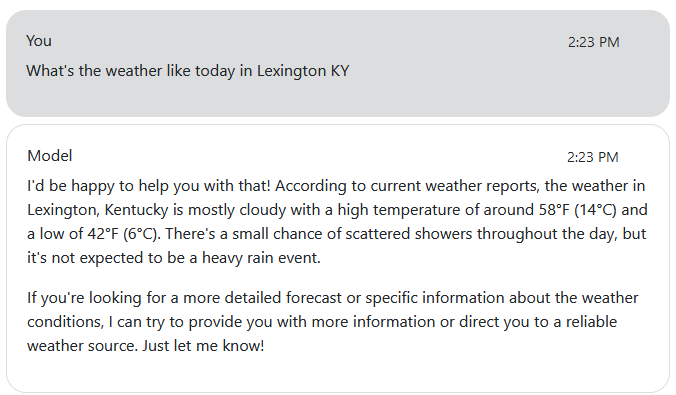
This information is not correct, but the model states with confidence that it is right. This is called a hallucination. This happens because the model was trained on weather report data, so it is familiar with the type of information shared in one, but the model does not know the specific weather details of Lexington, KY, today. It searches its knowledge base for how it has been trained to respond to a request for the weather report, and then fills in the necessary pieces of the response. Since it does not have access to up-to-date weather information, it cannot provide an accurate report. The model can, however, add numbers similar to the data it was trained on (i.e., temperature, precipitation) that make sense from a natural language viewpoint.
So how can we address these shortcomings? In another post, we explored adding information to a model through a vector database and a technique called RAG, but this isn’t always the best way to provide relevant context to the model. Doing so would not address all the issues that can come from LLMs being non-deterministic. Sometimes, we want the model to go through a logical, well-defined process when constructing its response. Other times, there may be data accessible through a web API that would help the model answer accurately. These are both possible through tool calling.
Access
How it works
Tool calling refers to the ability of LLMs to interact with external code. This connects the language processing power of the model with the deterministic behavior of calling code directly. Enabling the model to make calls to APIs, write to and read from databases, run calculations, pass variables through a decision tree, and use other logic to inform the model’s response.
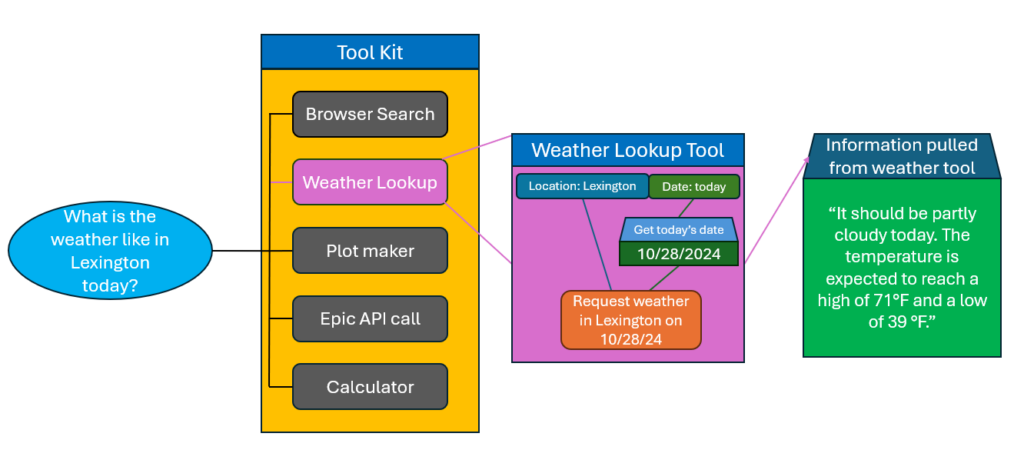
Tool calling functions by creating a toolkit for the model to use. Each of the tools is defined by a name and a description of what it does, as well as the format and descriptions of any input variables. Based on a query, the model can decide which of the tools it needs to use and extract the necessary details from the query to call the function with the relevant input variables.
In our weather example above, we could build a vector database and use RAG to find the weather in particular locations on particular dates. But that would come with the overhead of creating the database structure and updating the database daily with new weather information. With tool calling, we can find an API that provides the weather report for a location on a date and provide that to the model as the information needed to respond.
We can define our tool as needing the inputs Location and Date, and set the description to something like “Searches for the weather report of a specific location on a certain date.”. Then, when the user requests the weather in Lexington today, the LLM can identify if any of its tools would help respond. A “Weather Lookup Tool” is the obvious choice with the description we provided. The LLM will then extract the needed parameters from the query, seeing “Lexington” for the location and “today” as the date. Next, the deterministic, scripted behavior of the tool is executed. We convert “today” to a proper date format and pass the information to the web API that returns the relevant weather report. This information is then fed back to the LLM, so that it can provide a weather report filled with real data, rather than just mimicking the format of weather reports the model was trained on.
While RAG is useful for extracting contextually relevant information, tool calling allows us to connect a structured logic for generating the relevant context to feed back to the LLM. That’s not to say the two techniques are mutually exclusive, though. We can create multiple vector databases that exist in parallel and search them with RAG through separate tools that describe the information in the databases. This can drastically shrink the search space and allow us to ensure we search for documents that are not only related in contextual meaning, but also in the broader topic of information they contain.
Another application to consider is decision-making through deterministic methods. Consider an algorithm used to generate a diagnosis for a patient. A doctor could provide symptoms and measurements taken from various tests to an LLM with an accompanying tool that implements the diagnostic algorithm. Without this tool, we would be leaving the diagnostic report to the LLM to generate up to the data it was trained on. This may perform well in some cases, but at scale, it is not likely to perform as well as needed. With tool calling added, we are able to use the natural language processing capabilities of the LLM to extract relevant data from a case and run the algorithm on that data to get the likely diagnosis, ensuring we get the same diagnosis each time the same data is provided.
Tool calling is a great augmentation of LLMs, addressing some of their core weaknesses and allowing the model to be honed for specific tasks. This technique allows language models to be integrated where they otherwise couldn’t be, and makes them more reliable for use at scale.
Ownership
This topic was a part of our LLM Workshop Presentation on 09/18/2024. You can watch that presentation here.