Summary
Classifying patient scenarios for esophageal reflux disease using LLMs has faced significant challenges. LLMs focus on natural language but struggle to decipher and process numerical data. Interpreting precise and complex numerical data is critical for accurate diagnosis.
Previously, Dr. Bahaaeldeen Ismail’s group studied the challenges of using LLMs in esophageal reflux diagnosis. This project aims to develop and assess a hybrid LLM-supported pipeline for healthcare use by combining RAG techniques with tool calling. This hyper-specific LLM must accurately interpret esophageal tests and triage protocols to group patients based on their symptoms and labs. We have created a step-by-step system that utilizes a rule-based decision support system to extract and analyze LLM-based data.
We found that hybrid pipelines using LLMs had success in deciphering many esophageal tests using synthetic case scenarios inspired by real-world patient data.
Our pipeline was tested using OpenAI 40-mini and Llama 3.1 (70B).
Datasets/Model
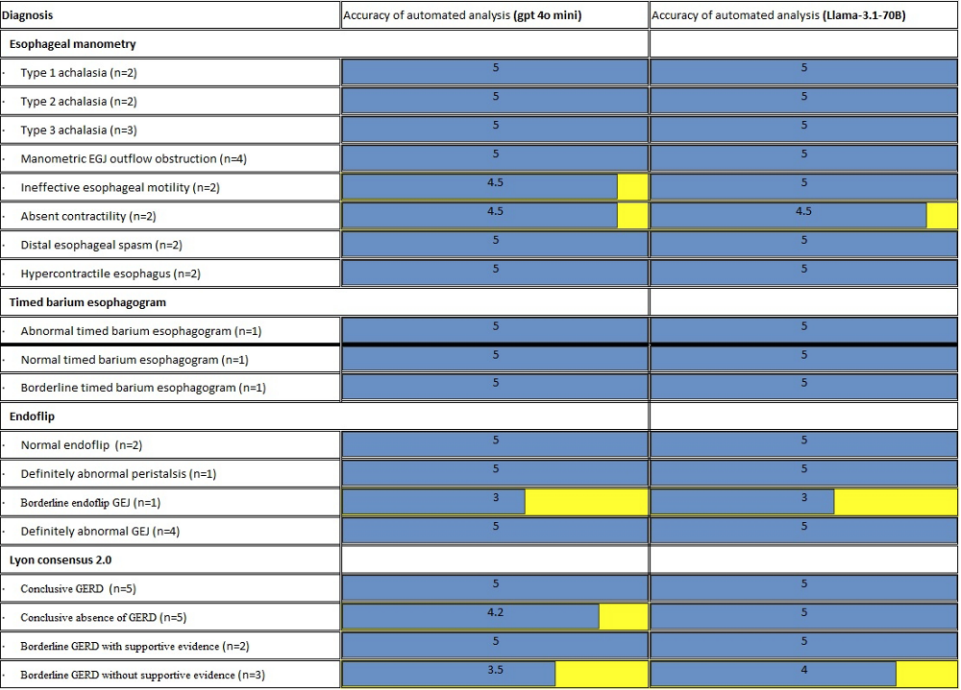
Our pipeline was tested using OpenAI 40-mini and Llama 3.1 (70B). Modeled after patients at the University of Kentucky’s esophageal clinic, 30 case scenarios were used. The pipeline’s performance was tested on these case scenarios, with 14 simple cases (single test) and 16 complex cases (2-3 tests). These answers were rated by an independent evaluator on a scale of 1-5, with 1 being completely incorrect and 5 being accurate on an expert level. Of the 30 cases evaluated, there were 51 test interpretations. This included 21 high-resolution manometries, 15 reflux tests, 9 EndoFLIP assessments, and 6 timed barium esophagograms.
As exhibited in Table 1, the specific diagnoses with average ratings from each model are detailed. Both models achieved a median rating of 5 (expert-level accuracy). The OpenAI model’s range 1-5, and the Llama 3.1 model’s range 3-5. Thus, presenting no statistically significant differences between the performance of the two models. Figure 1 demonstrates that the performance consistency of the results was maintained across all categories from both models. However, there are subtle differences in complex cases between the two models. For instance, cases such as “borderline EndoFLIP” and “borderline Lyon consensus’. By using tool calling with LangChain, we were able to get structured values from unstructured text. We then passed those values through an algorithm to get a diagnosis.

Access
The data used for this project is restricted and not publicly available.
Ownership
This project has been completed.
The study can be found at:
CAAI member Mitchell Klusty worked on Comparative Assessment of a Hybrid LLM-Backed Pipeline for Esophageal Test Interpretation: Commercial vs. Open-Source Models